한동수 교수팀, 최적 머신러닝 인덱싱 검색 기법을 유전체 정렬 소프트웨어에 적용
10년간 사용되던 인덱싱 기법보다 3.4배 빠른 것으로 알려져
유전체 정렬 소프트웨어는 오픈소스로 공개
[데일리포스트=김정은 기자] "이번 연구를 통해 기계학습 기술을 접목해 전장 유전체 빅데이터 분석을 기존 방식보다 빠르고 적은 비용으로 할 수 있다는 것을 보여줬으며, 앞으로 인공지능 기술을 활용해 전장 유전체 빅데이터 분석을 효율화, 고도화할 수 있을 것으로 기대됩니다"(KAIST 한동수 교수)
KAIST는 전기및전자공학부 한동수 교수 연구팀이 머신러닝(기계학습)에 기반한 *유전체 정렬 소프트웨어를 개발했다고 12일 밝혔다.
☞ 유전체(genome): 생명체가 가지고 있는 염기서열 정보의 총합이며, 유전자는 생물학적 특징을 발현하는 염기서열들을 지칭한다. 유전체를 한 권의 책이라고 비유하면 유전자는 공백을 제외한 모든 글자라고 비유할 수 있다.
차세대 염기서열 분석은 유전체 정보를 해독하는 방법으로 유전체를 무수히 많은 조각으로 잘라낸 후 각 조각을 참조 유전체(reference genome)에 기반해 조립하는 과정을 거친다. 조립된 유전체 정보는 암을 포함한 여러 질병의 예측과 맞춤형 치료, 백신 개발 등 다양한 분야에서 사용된다.
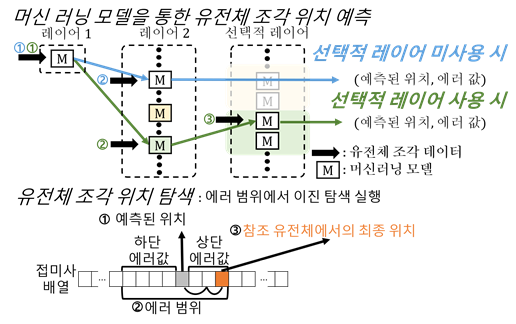
유전체 정렬 소프트웨어는 차세대 염기서열 분석 방법으로 생성한 유전체 조각 데이터를 온전한 유전체 정보로 조립하기 위해 사용되는 소프트웨어다. 유전체 정렬 작업에는 많은 연산이 들어가며, 속도를 높이고 비용을 낮추는 방법에 관한 관심이 계속해서 증가하고 있다. 머신러닝(기계학습) 기반의 인덱싱(색인) 기법(Learned-index)을 유전체 정렬 소프트웨어에 적용한 사례는 이번이 최초다.

KAIST 전기및전자공학부 정영목 박사과정이 제1 저자로 참여한 이번 연구는 국제 학술지 `옥스포드 바이오인포메틱스(Oxford Bioinformatics)' 2022년 3월에 공개됐다. (논문명 : BWA-MEME: BWA-MEM emulated with a machine learning approach)
유전체 정렬 작업은 정렬해야 하는 유전체 조각의 양이 많고 참조 유전체의 길이도 길어 많은 연산량이 요구되는 작업이다. 또한, 유전체 정렬 소프트웨어에서 정렬 결과의 정확도에 따라 추후의 유전체 분석의 정확도가 영향을 받는다. 이러한 특성 때문에 유전체 정렬 소프트웨어는 높은 정확성을 유지하며 빠르게 연산하는 것이 중요하다.
일반적으로 유전체 분석에는 하버드 브로드 연구소(Broad Institute)에서 개발한 유전체 분석 도구 키트(Genome Analysis Tool Kit, 이하 GATK)를 이용한 데이터 처리 방법을 표준으로 사용한다. 이들 키트 중 BWA-MEM은 GATK에서 표준으로 채택한 유전체 정렬 소프트웨어이며, 2019년에 하버드 대학과 인텔(Intel)의 공동 연구로 BWA-MEM2가 개발됐다.
연구팀이 개발한 머신러닝 기반의 유전체 정렬 소프트웨어는 연산량을 대폭 줄이면서도 표준 유전체 정렬 소프트웨어 BWA-MEM2과 동일한 결과를 만들어 정확도를 유지했다. 사용한 머신러닝 기반의 인덱싱 기법은 주어진 데이터의 분포를 머신러닝 모델이 학습해, 데이터 분포에 최적화된 인덱싱을 찾는 방법론이다. 데이터에 적합하다고 생각되는 인덱싱 방법을 사람이 정하던 기존의 방법과 대비된다.
BWA-MEM과 BWA-MEM2에서 사용하는 인덱싱 기법(FM-index)은 유전자 조각의 위치를 찾기 위해 유전자 조각 길이만큼의 연산이 필요하지만, 연구팀이 제안한 알고리즘은 머신러닝 기반의 인덱싱 기법(Learned-index)을 활용해, 유전자 조각 길이와 상관없이 적은 연산량으로도 유전자 조각의 위치를 찾을 수 있다. 연구팀이 제안한 인덱싱 기법은 기존 인덱싱 기법과 비교해 3.4배 정도 가속화됐고, 이로 인해 유전체 정렬 소프트웨어는 1.4 배 가속화됐다.
연구팀이 이번 연구에서 개발한 유전체 정렬 소프트웨어는 오픈소스로 공개돼 많은 분야에 사용될 것으로 기대되며, 유전체 분석에서 사용되는 다양한 소프트웨어를 머신러닝 기술로 가속화하는 연구들의 초석이 될 것으로 기대된다.
한편 이번 연구는 과학기술정보통신부의 재원으로 한국연구재단의 지원을 받아 데이터 스테이션 구축·운영 사업으로서 수행됐다.